La téléconduite des réseaux de distribution dans les années 80
Article paru en 1984 dans la revue Épure de la Direction des Études et Recherches sur la téléconduite des réseaux de distribution
0 commentaire
29 janvier 2021




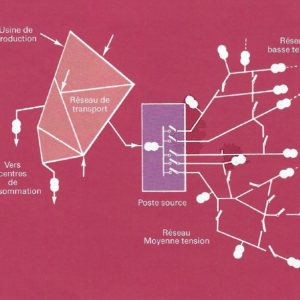
Article paru en 1984 dans la revue Épure de la Direction des Études et Recherches sur la téléconduite des réseaux de distribution

Cet équipement « Système IV » de CGCT (Compagnie Générale de Constructions Téléphoniques) permet la transmission à distance d'informations binaires simples (ordre ou signalisation) entre deux points. Une armoire est…

La téléalarme Techniphone dite "50 Hz" a été un des premiers outils normalisé de l'évolution du mode d'exploitation des postes électriques haute tension.. Ces téléalarmes ont fait l'objet de spécifications…

La téléalarme se présente sous forme d’un coffret métallique qui peut être mis en place verticalement contre un mur ou accroché à un répartiteur téléphonique. Quatre alarmes peuvent être transmises…

C'’est un équipement permettant la téléconduite d'’ouvrages électriques, en particulier des postes HT/THT du Transport d'Énergie d’EDF. Il se présente sous forme d’une baie mise en place à chaque extrémité…

Cet appareil convertisseur analogique numérique, de marque Lepaute, fait partie d’un équipement de télémesure multivoie qui a été installé à la fin des années 50 entre des postes Haute Tension et…

Le DARC (Diffuseur d'alarmes à recherche cyclique) Degréane est installé dans une baie technique standard 19 pouces. Les différents châssis sont fixés par l'avant: alimentation en bas, tambour magnétique au…

Pupitre Mitra 15 Le Mitra 15 est un mini ordinateur 16 bits temps réel de technologie TTL qui comporte une mémoire principale à tores…

Le projet dénommé ‟ informations codées“ a été déployé à partir de 1966 par EDF afin d’assurer la surveillance et l’exploitation du réseau électrique de transport d’énergie à Haute et…
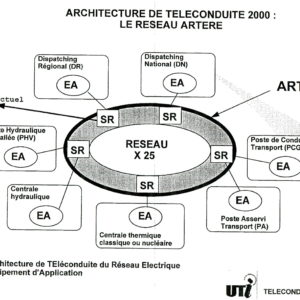
Le contexte à EDF : le Programme Téléconduite 2000 La fin du déploiement des SIRC marque la fin du déploiement du SDART. En 1990, lui succède un ambitieux programme…